

从零搭建 K8s 使用 NVIDIA GPU 的环境
在搭建k8s后,如果集群包含 GPU 节点并且需要运行的 Pod(比如模型服务)使用 GPU 资源,除了 Kubernetes 的常规组件,还需要在集群中安装并配置与 GPU 相关的环境与服务。
一、GPU 节点环境准备
首先需要给 GPU 服务器安装驱动,并给容器运行时安装 nvidia-container-toolkit
下面的步骤基于 Ubuntu 22.04 操作系统
1.1 安装 GPU 驱动
如果需要安装 CUDA 可以跳过 1.1.1~1.1.3,直接查看「1.1.4 安装 CUDA」部分,CUDA 安装包中会包含GPU驱动
1.1.1 确认 GPU 显卡型号
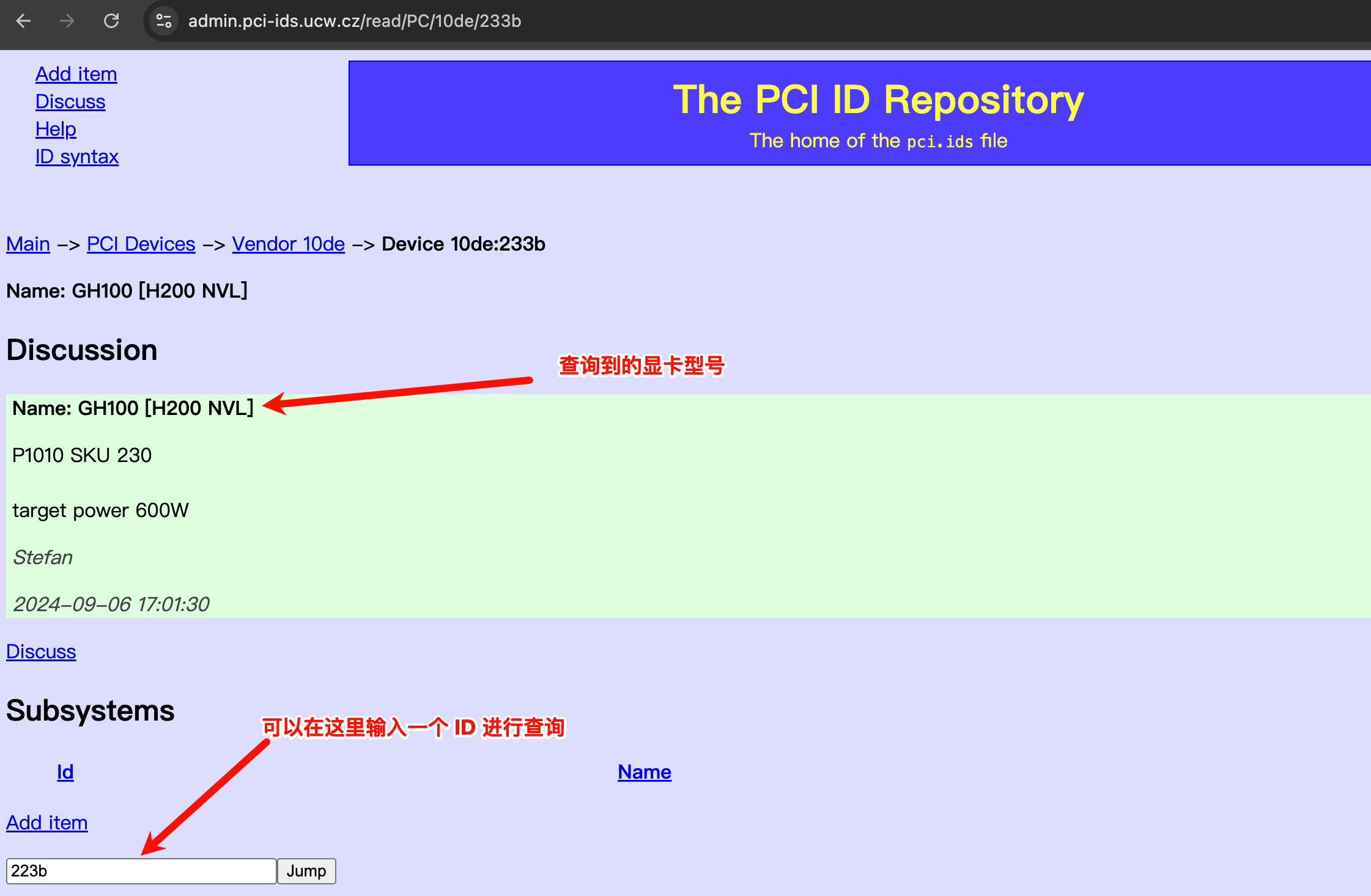
装驱动之前需要先知道 GPU 卡是什么型号的然后去下载对应的驱动文件,但是有的时候并不明确知道GPU卡是什么型号的,就需要手动查一下
lspci | grep -i NVIDIA
04:00.0 VGA compatible controller: NVIDIA Corporation GA102 [GeForce RTX 3090] (rev a1)
04:00.1 Audio device: NVIDIA Corporation GA102 High Definition Audio Controller (rev a1)

如果没有装驱动的话,在这个位置看到的可能是四个字母和数字组成的ID(十六进制),比如:233b
打开下面的网页:
- Nvidia PCI ID设备:https://admin.pci-ids.ucw.cz/mods/PC/10de
- 指定ID页面(可以在这个页面输入其他ID进行查询):https://admin.pci-ids.ucw.cz/read/PC/10de/2203
在页面中输入ID即可查找到对应的 Nvidia 显卡型号
1.1.2 下载 GPU 驱动
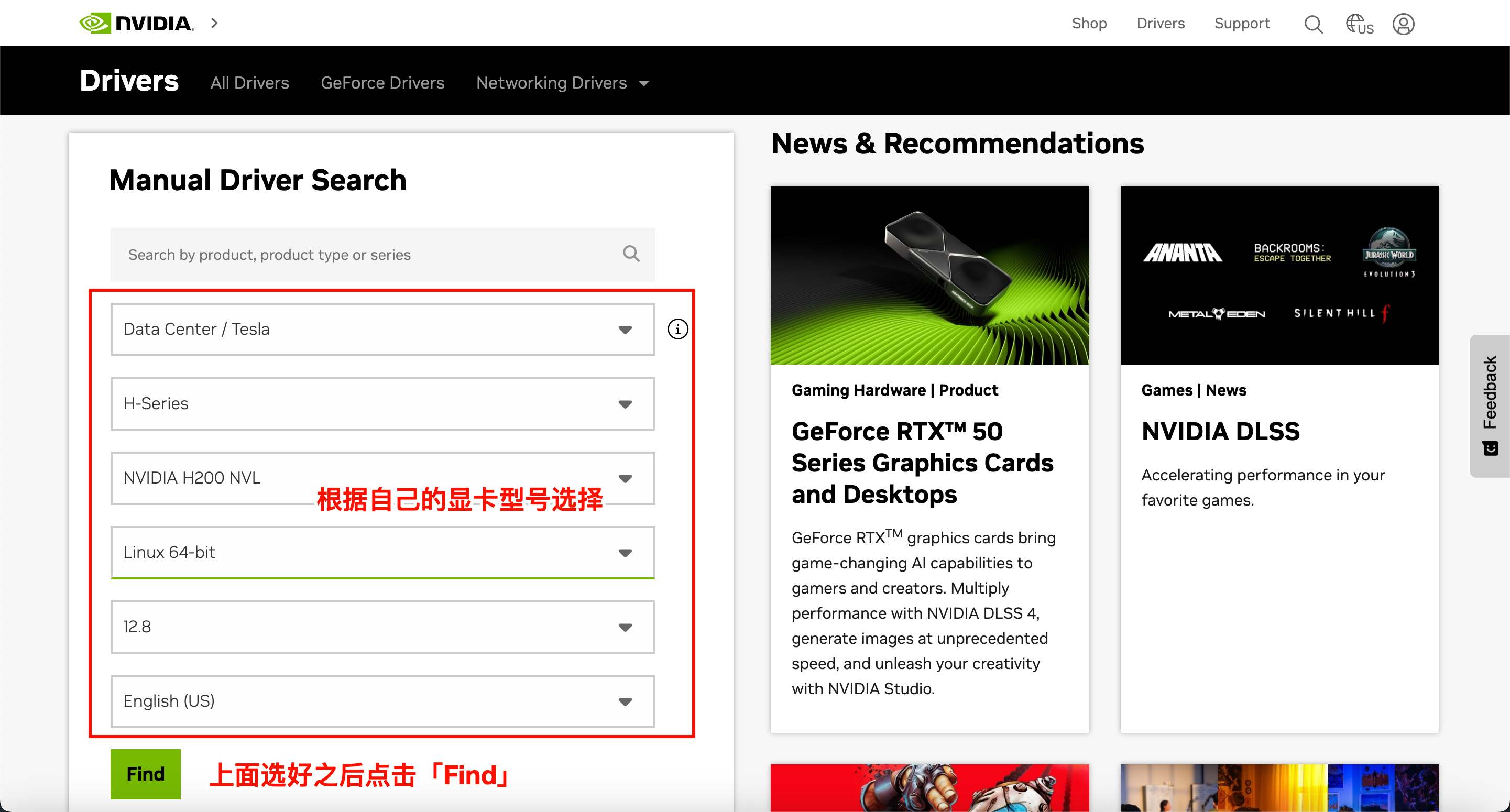
去这个网站查找并下载驱动:https://www.nvidia.com/en-us/drivers/
1、根据自己的显卡型号选择,选择完之后点击「Find」
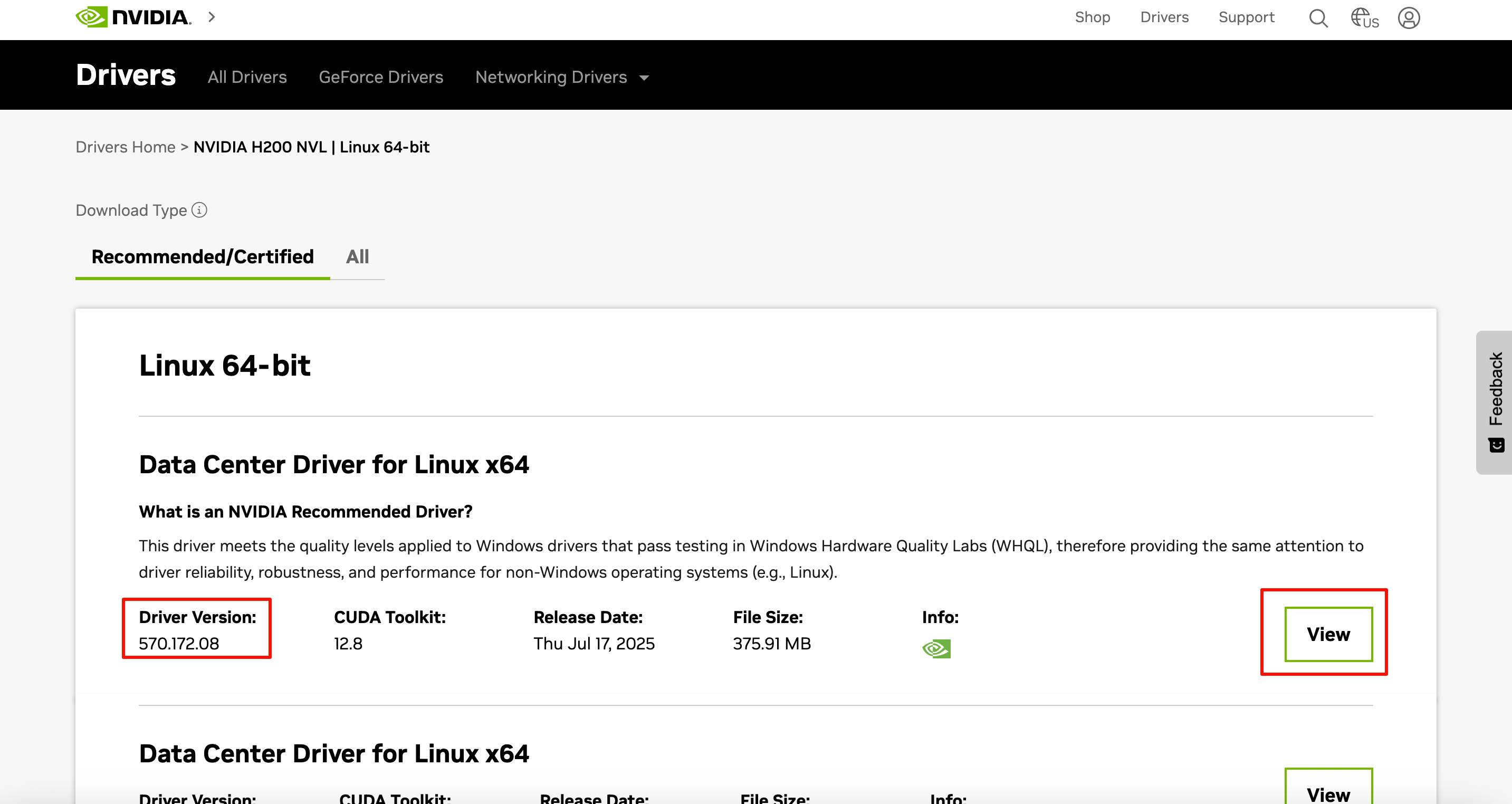
2、选择驱动版本(一般选择第一个即可,推荐最好确认下业务应用的需求),然后选择「View」
3、下载驱动
进入到下载界面后,点击「Download」下载即可

1.1.3 安装 GPU 驱动
chmod +x NVIDIA-Linux-x86_64-570.172.08.run
./NVIDIA-Linux-x86_64-570.172.08.run
驱动安装完成之后可以执行下面命令查看显卡信息
# 执行 nvidia-smi 需要比较长的时间才能输出结果,先执行这个可以比较快的输出结果
nvidia-persistenced
nvidia-smi
1.1.4 安装CUDA
CUDA 安装包会包含 GPU 驱动,如果安装 CUDA 的话,可以跳过上面的步骤
去这个网页选择对应的 CUDA 版本:https://developer.nvidia.com/cuda-toolkit-archive
根据自己的架构、操作系统及版本选择之后即可看到下载链接和安装命令
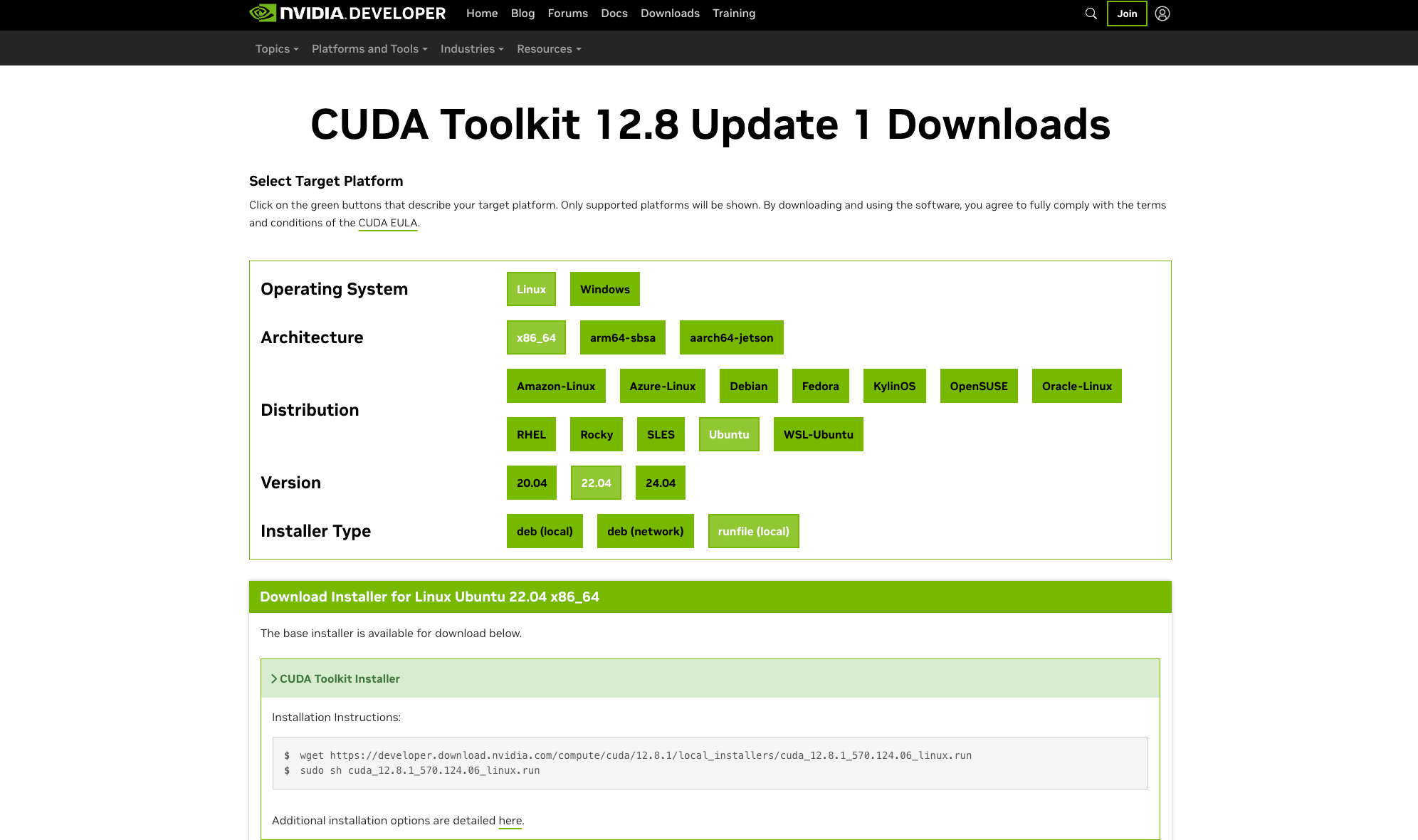
执行
wget https://developer.download.nvidia.com/compute/cuda/12.8.1/local_installers/cuda_12.8.1_570.124.06_linux.run
sudo sh cuda_12.8.1_570.124.06_linux.run
安装完成之后通过下面命令检查
nvcc -V
nvidia-smi
1.1.5 安装 nvitop
nvitop是一个非常全面的NVIDIA-GPU设备运行状况的实时监控工具,它将GPU利用率,显存占比,卡号使用者,CPU利用率,进程使用时间,命令行等等集于一身,并以差异化的颜色进行个性化展示,安装过程也非常简单
pip3 install --upgrade nvitop
nvitop
1.2 安装 Nvidia-container-toolkit
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
如果需要运行使用 GPU 资源的容器,则需要安装 nvidia-container-toolkit
1、配置源
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
2、安装 nvidia-container-toolkit
export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1
sudo apt-get install -y \
nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}
3、配置容器运行时
Docker:
sudo nvidia-ctk runtime configure --runtime=docker --set-as-default
sudo systemctl restart docker
Containerd:
sudo nvidia-ctk runtime configure --runtime=containerd --set-as-default
sudo systemctl restart containerd
二、在 Kubernetes 中安装 NVIDIA Device Plugin
在 k8s 中,如果需要调度并正常运行使用 Nvidia GPU 资源的 Pod,需要安装一个 Nvidia 的 k8s-device-plugin,会以 DaemonSet 的形式在每个节点上运行一个 Pod
2.1 安装
2.1.1 方式一:通过 yaml 安装
k8s-device-plugin 实际上只有一个 DaemonSet,可以直接通过 apply yaml 的方式安装
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.17.4/deployments/static/nvidia-device-plugin.yml
# 查看 Pod
kubectl get pods -n kube-system -l name=nvidia-device-plugin-ds
2.1.2 方式二:通过 Helm 安装
通过 Helm 方式安装,会额外安装 node-feature-discovery
1、准备 helm repo
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
2、安装 nvidia-device-plugin
helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace nvidia-device-plugin \
--create-namespace
kubectl get pods -n nvidia-device-plugin
2.2 查看GPU节点资源
安装 device-plugin 之后,describeGPU节点将会看到有GPU相关的资源
kubectl describe node <gpu-node>
...
Capacity:
nvidia.com/gpu: 8
...
三、运行使用 GPU 的 Pod
3.1 运行示例 Pod
安装过上面那些组建之后,运行一个简单的使用 Nvidia GPU 资源的 Pod 来验证环境是否可用
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda12.5.0
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
EOF
查看日志
kubectl logs gpu-pod
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
3.2 确定 Pod 使用指定的 Nvidia 卡
在有些场景下,如果想要让使用 GPU 资源的 Pod 运行在节点上指定的 GPU 卡上,可以通过NVIDIA_VISIBLE_DEVICES变量来指定卡号
containers:
- env:
- name: CUDA_VISIBLE_DEVICES
value: "5"
name: vllm
resources:
limits:
nvidia.com/gpu: "1"
requests:
nvidia.com/gpu: "1"
在对应节点上执行 nvidia-smi 或者 nvitop 将会看到 Pod 使用的是卡号为 5 的卡


